高通過率的MLA-C01證照資訊:AWS Certified Machine Learning Engineer - Associate &有效Amazon MLA-C01最新考證
Wiki Article
P.S. KaoGuTi在Google Drive上分享了免費的2026 Amazon MLA-C01考試題庫:https://drive.google.com/open?id=1CMroklG2xCo4PtZuxiVYcbQ0zjWIVTTB
我們KaoGuTi配置提供給你最優質的Amazon的MLA-C01考試考古題及答案,將你一步一步帶向成功,我們KaoGuTi Amazon的MLA-C01考試認證資料絕對提供給你一個真實的考前準備,我們針對性很強,就如同為你量身定做一般,你一定會成為一個有實力的IT專家,我們KaoGuTi Amazon的MLA-C01考試認證資料將是最適合你也是你最需要的培訓資料,趕緊註冊我們KaoGuTi網站,相信你會有意外的收穫。
Amazon MLA-C01 考試大綱:
| 主題 | 簡介 |
|---|---|
| 主題 1 |
|
| 主題 2 |
|
| 主題 3 |
|
| 主題 4 |
|
MLA-C01最新考證 - MLA-C01考證
你是一名IT人員嗎?你報名參加當今最流行的IT認證考試了嗎?如果你是,我將告訴你一個好消息,你很幸運,我們KaoGuTi Amazon的MLA-C01考試認證培訓資料可以幫助你100%通過考試,這絕對是個真實的消息。如果你想在IT行業更上一層樓,選擇我們KaoGuTi那就更對了,我們的培訓資料可以幫助你通過所有有關IT認證的,而且價格很便宜,我們賣的是適合,不要不相信,看到了你就知道。
最新的 AWS Certified Associate MLA-C01 免費考試真題 (Q122-Q127):
問題 #122
An advertising company uses AWS Lake Formation to manage a data lake. The data lake contains structured data and unstructured data. The company's ML engineers are assigned to specific advertisement campaigns.
The ML engineers must interact with the data through Amazon Athena and by browsing the data directly in an Amazon S3 bucket. The ML engineers must have access to only the resources that are specific to their assigned advertisement campaigns.
Which solution will meet these requirements in the MOST operationally efficient way?
- A. Configure S3 bucket policies to restrict access to the S3 bucket based on the ML engineers' campaigns.
- B. Configure IAM policies on an AWS Glue Data Catalog to restrict access to Athena based on the ML engineers' campaigns.
- C. Use Lake Formation to authorize AWS Glue to access the S3 bucket. Configure Lake Formation tags to map ML engineers to their campaigns.
- D. Store users and campaign information in an Amazon DynamoDB table. Configure DynamoDB Streams to invoke an AWS Lambda function to update S3 bucket policies.
答案:C
解題說明:
AWS Lake Formation provides fine-grained access control and simplifies data governance for data lakes. By configuring Lake Formation tags to map ML engineers to their specific campaigns, you can restrict access to both structured and unstructured data in the data lake. This method is operationally efficient, as it centralizes access control management within Lake Formation and ensures consistency across Amazon Athena and S3 bucket access without requiring manual updates to policies or DynamoDB-based custom logic.
問題 #123
A company wants to host an ML model on Amazon SageMaker. An ML engineer is configuring a continuous integration and continuous delivery (Cl/CD) pipeline in AWS CodePipeline to deploy the model. The pipeline must run automatically when new training data for the model is uploaded to an Amazon S3 bucket.
Select and order the pipeline's correct steps from the following list. Each step should be selected one time or not at all. (Select and order three.)
* An S3 event notification invokes the pipeline when new data is uploaded.
* S3 Lifecycle rule invokes the pipeline when new data is uploaded.
* SageMaker retrains the model by using the data in the S3 bucket.
* The pipeline deploys the model to a SageMaker endpoint.
* The pipeline deploys the model to SageMaker Model Registry.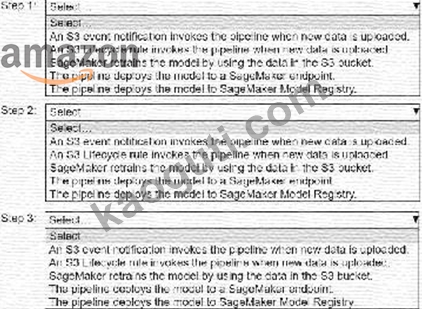
答案:
解題說明: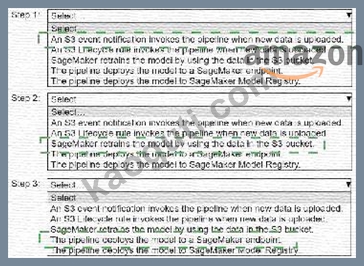
Explanation:
Step 1: An S3 event notification invokes the pipeline when new data is uploaded.
Step 2: SageMaker retrains the model by using the data in the S3 bucket.
Step 3: The pipeline deploys the model to a SageMaker endpoint.
* Step 1: An S3 Event Notification Invokes the Pipeline When New Data is Uploaded
* Why? The CI/CD pipeline should be triggered automatically whenever new training data is uploaded to Amazon S3. S3 event notifications can be configured to send events to AWS services like Lambda, which can then invoke AWS CodePipeline.
* How? Configure the S3 bucket to send event notifications (e.g., s3:ObjectCreated:*) to AWS Lambda, which in turn triggers the CodePipeline.
* Step 2: SageMaker Retrains the Model by Using the Data in the S3 Bucket
* Why? The uploaded data is used to retrain the ML model to incorporate new information and maintain performance. This step is critical to updating the model with fresh data.
* How? Define a SageMaker training step in the CI/CD pipeline, which reads the training data from the S3 bucket and retrains the model.
* Step 3: The Pipeline Deploys the Model to a SageMaker Endpoint
* Why? Once retrained, the updated model must be deployed to a SageMaker endpoint to make it available for real-time inference.
* How? Add a deployment step in the CI/CD pipeline, which automates the creation or update of the SageMaker endpoint with the retrained model.
Order Summary:
* An S3 event notification invokes the pipeline when new data is uploaded.
* SageMaker retrains the model by using the data in the S3 bucket.
* The pipeline deploys the model to a SageMaker endpoint.
This configuration ensures an automated, efficient, and scalable CI/CD pipeline for continuous retraining and deployment of the ML model in Amazon SageMaker.
問題 #124
A company wants to improve the sustainability of its ML operations.
Which actions will reduce the energy usage and computational resources that are associated with the company
' s training jobs? (Choose two.)
- A. Use Amazon SageMaker Ground Truth for data labeling.
- B. Use AWS Trainium instances for training.
- C. Deploy models by using AWS Lambda functions.
- D. Use Amazon SageMaker Debugger to stop training jobs when non-converging conditions are detected.
- E. Use PyTorch or TensorFlow with the distributed training option.
答案:B,D
解題說明:
SageMaker Debugger can identify when a training job is not converging or is stuck in a non-productive state.
By stopping these jobs early, unnecessary energy and computational resources are conserved, improving sustainability.
AWS Trainium instances are purpose-built for ML training and are optimized for energy efficiency and cost- effectiveness. They use less energy per training task compared to general-purpose instances, making them a sustainable choice.
問題 #125
An ML engineer is using Amazon SageMaker to train a deep learning model that requires distributed training.
After some training attempts, the ML engineer observes that the instances are not performing as expected. The ML engineer identifies communication overhead between the training instances.
What should the ML engineer do to MINIMIZE the communication overhead between the instances?
- A. Place the instances in the same VPC subnet but in different Availability Zones. Store the data in a different AWS Region from where the instances are deployed.
- B. Place the instances in the same VPC subnet. Store the data in the same AWS Region and Availability Zone where the instances are deployed.
- C. Place the instances in the same VPC subnet. Store the data in the same AWS Region but in a different Availability Zone from where the instances are deployed.
- D. Place the instances in the same VPC subnet. Store the data in a different AWS Region from where the instances are deployed.
答案:B
解題說明:
To minimize communication overhead during distributed training:
1. Same VPC Subnet: Ensures low-latency communication between training instances by keeping the network traffic within a single subnet.
2. Same AWS Region and Availability Zone: Reduces network latency further because cross-AZ communication incurs additional latency and costs.
3. Data in the Same Region and AZ: Ensures that the training data is accessed with minimal latency, improving performance during training.
This configuration optimizes communication efficiency and minimizes overhead.
問題 #126
A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company's Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
- A. Create an S3 Lifecycle rule to transfer the data to the SageMaker training instance and to initiate training.
- B. Use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to orchestrate the pipeline when new data is uploaded.
- C. Create an AWS Lambda function that scans the S3 bucket. Program the Lambda function to initiate the pipeline when new data is uploaded.
- D. Create an Amazon EventBridge rule that has an event pattern that matches the S3 upload. Configure the pipeline as the target of the rule.
答案:D
解題說明:
UsingAmazon EventBridgewith an event pattern that matches S3 upload events provides an automated, low- effort solution. When new data is uploaded to the S3 bucket, the EventBridge rule triggers the SageMaker pipeline. This approach minimizes operational overhead by eliminating the need for custom scripts or external orchestration tools while seamlessly integrating with the existing S3 and SageMaker setup.
問題 #127
......
MLA-C01 考題寶典由 KaoGuTi 在世界各地的資深IT工程師組成的專業團隊製作完成,Amazon 的 MLA-C01 考題寶典內包含最新的 MLA-C01 考試試題,並附有全部正確答案,保證一次輕鬆通過 MLA-C01 考試,完全無需購買其他額外的MLA-C01 複習資料。並且購買 MLA-C01 考題後,享有一年的免費更新服務。
MLA-C01最新考證: https://www.kaoguti.com/MLA-C01_exam-pdf.html
- MLA-C01考證 ???? MLA-C01考試內容 ???? MLA-C01考試內容 ◀ 請在✔ www.pdfexamdumps.com ️✔️網站上免費下載✔ MLA-C01 ️✔️題庫MLA-C01考古題分享
- MLA-C01認證 ???? 最新MLA-C01題庫 ???? MLA-C01證照考試 ???? 複製網址✔ www.newdumpspdf.com ️✔️打開並搜索☀ MLA-C01 ️☀️免費下載MLA-C01題庫更新
- 真實的MLA-C01證照資訊 |第一次嘗試輕鬆學習並通過考試,可信的MLA-C01:AWS Certified Machine Learning Engineer - Associate ???? 複製網址⏩ www.testpdf.net ⏪打開並搜索「 MLA-C01 」免費下載最新MLA-C01試題
- MLA-C01認證考試資料 ⛹ 進入▶ www.newdumpspdf.com ◀搜尋➥ MLA-C01 ????免費下載MLA-C01考試內容
- MLA-C01題庫更新 ???? MLA-C01題庫更新 ???? MLA-C01考題套裝 ✴ 開啟➥ www.newdumpspdf.com ????輸入( MLA-C01 )並獲取免費下載MLA-C01最新考證
- 真實的MLA-C01證照資訊 |第一次嘗試輕鬆學習並通過考試,可信的MLA-C01:AWS Certified Machine Learning Engineer - Associate ???? ▛ www.newdumpspdf.com ▟上的➽ MLA-C01 ????免費下載只需搜尋MLA-C01認證
- 值得信任的MLA-C01證照資訊擁有模擬真實考試環境與場境的軟件VCE版本&優秀的Amazon MLA-C01 ???? 開啟▷ www.kaoguti.com ◁輸入“ MLA-C01 ”並獲取免費下載MLA-C01软件版
- MLA-C01考試內容 ???? MLA-C01考古題分享 ♣ 最新MLA-C01試題 ???? 立即到“ www.newdumpspdf.com ”上搜索➡ MLA-C01 ️⬅️以獲取免費下載MLA-C01熱門考古題
- MLA-C01認證考試的最新題庫 - 高命中率的MLA-C01考古題 ???? 透過[ www.newdumpspdf.com ]輕鬆獲取☀ MLA-C01 ️☀️免費下載最新MLA-C01題庫資源
- 實用的MLA-C01證照資訊&保證Amazon MLA-C01考試成功與全面覆蓋的MLA-C01最新考證 ???? 免費下載➽ MLA-C01 ????只需進入➥ www.newdumpspdf.com ????網站MLA-C01软件版
- 最新有效的MLA-C01學習指南資料 - 提供免费的MLA-C01試題下載 ⏮ { www.pdfexamdumps.com }最新▷ MLA-C01 ◁問題集合MLA-C01權威認證
- zaynnbrq301155.blogdemls.com, netwebdirectory.com, tessppju140120.blogtov.com, bookmarkfavors.com, harmonydtzp581488.thenerdsblog.com, qasimhesp383760.iyublog.com, sitesrow.com, seobookmarkpro.com, hannalouu408630.blogoxo.com, socialaffluent.com, Disposable vapes
從Google Drive中免費下載最新的KaoGuTi MLA-C01 PDF版考試題庫:https://drive.google.com/open?id=1CMroklG2xCo4PtZuxiVYcbQ0zjWIVTTB
Report this wiki page